3.1 EL SURGIMIENTO DE LA WEB. OBJETIVOS
INICIALES

“La Word Wide Web”
Internet
Internet es una gran red de redes,
también llamada Supercarretera de la información. Es el resultado de la
interconexión de miles de computadoras de todo el mundo. Todas ellas comparten
los protocolos de comunicación, es decir que todos hablan el mismo lenguaje
para ponerse en contacto unas con otras.
Los servicios básicos ofrecidos ahora
por Internet son correo electrónico, noticias en red, acceso a computadoras
remotas y sistemas de adquisición de datos, y la capacidad para transferir
información entre computadoras remotas.
Historia de la Web
La Web es una idea que se construyo
sobre la Internet. Las conexiones físicas son sobre la Internet, pero introduce
una serie de ideas nuevas, heredando las ya existentes.
Empezó a principios de 1990, en Suiza
en el centro de investigación CERN (centro de Estudios para la Investigación
Nuclear) y la idea fue de Tim Berners-Lee, que se gestó observando una libreta
que él usaba para añadir y mantener referencias de cómo funcionaban los
ordenadores en el CERN.
Antes de la Web, la manera de obtener
los datos por la Internet era caótica: había un sinfín de maneras posibles y
con ello había que conocer múltiples programas y sistemas operativos. La Web
introduce un concepto fundamental: la posibilidad de lectura universal, que
consiste en que una vez que la información esté disponible, se pueda acceder a
ella desde cualquier ordenador, desde cualquier país, por cualquier persona
autorizada, usando un único y simple programa. Para que esto fuese posible, se
utilizan una serie de conceptos, el más conocido es el hipertexto.
Con Web los usuarios novatos podrían
tener un tremendo poder para hallar y tener acceso a la riqueza de información
localizada en sistemas de cómputos en todo el mundo.
Este solo hecho llevó un avance
tremendo de Internet, un ímpetu tan grande que en 1993 World Wide Web creció un
sorprendente 341000%, tres años después, en 1996, todavía sé esta duplicando
cada 50 días.
¿Qué es la World Wide Web o la
Web?
La World Wide Web consiste en ofrecer
una interface simple y consistente para acceder a la inmensidad de los recursos
de Internet. Es la forma más moderna de ofrecer información. el medio más
potente. La información se ofrece en forma de páginas electrónicas.
El World Wide Web o WWW o W3 o
simplemente Web, permite saltar de un lugar a otro en pos de lo que no
interesa. Lo más interesante es que con unas pocas ordenes se puede mover por
toda la Internet.
Para entender lo que es la Web debemos
tener una idea de lo que es el Hipertexto.
Hipertexto
Hipertexto son datos que contienen
enlaces (links) a otros datos.
En el lenguaje Web, un documento de
hipertexto no es solo algo que contiene datos, sino que además contiene enlaces
a otros documentos.
Un ejemplo simple de hipertexto es una
enciclopedia que al final de un tema tiene referencias de algún tema en
especial o referencias bibliográficas a otros textos.
En Hipertexto, el ordenador hace que
seguir esas referencias sea facilísimo. Esto implica que el lector se puede
saltar la estructura secuencial del texto y seguir lo que más le gusta.
En Hipertexto se pueden hacer enlaces
en cualquier lugar, no sólo al final.
Cada enlace tiene una marca que lo
destaca, puede estar resaltado, subrayado o puede estar identificado por un
número.
El hipertexto no esta limitado a datos
textuales, podemos encontrar dibujos del elemento especificado, sonido o vídeo
referido al tema. Estos documentos que tienen gran variedad de datos, como
sonido, vídeo, texto, en el mundo del hipertexto se llama hipermedia.
El hipertexto es una herramienta
potente para aprender y explicar. El texto debe ser diseñado para ser explorado
libremente y así se consigue una comunicación de ideas más eficientes.
Funcionamiento
de la Web
Una vez que el usuario esta conectado a
Internet, tiene que instalar un programa capaz de acceder a páginas Web y de
llevarte de unas a otras siguiendo los enlaces.
El programa que se usa para leer los
documentos de hipertexto se llama “navegador”, el “browser”, “visualizador” o
“cliente” y cuando seguimos un enlace decimos que estamos navegando por el Web.
Así, no hay más que buscar la
información o la página deseada y comenzar a navegar por las diferentes
posibilidades que ofrece el sistema.
Navegar es como llaman los usuarios de
la red a moverse de página en página por todo el mundo sin salir de su casa.
Mediante los Navegadores modernos
podemos, acceder a hojas de calculo, base de datos, vídeo, sonido y todas las
posibilidades más avanzadas. Pero el diseño de páginas debe mantener un
equilibrio entre utilizar todas las capacidades y la posibilidad de ser leídas
por cualquier tipo de Navegador.
El visualizador nos presentará
perfectamente cualquier página “.txt” generada por cualquier editor, y los
links entre documentos sólo requieren un simple y sencillo comando. Y aún así
podremos conseguir el tipo y tamaño de letra y colores de texto y fondo que
queramos, simplemente configurando el visualizador.
Navegadores que se utilizan
Los más conocidos son el Explorer de
Microsoft, Mosaic y el Netscape de Netscape Communications Corporation en
Estados Unidos y otros países. Tienen capacidades diferentes y es importante
cuando se crea una página Web, además de un buen diseño, tener en cuenta la
compatibilidad, es decir, programar páginas de modo que las acepte cualquier
Navegador.
Netscape es el que soporta más y
mejores efectos, incluido programas embebidos en el propio texto (versión 2.0
en adelante), escritos en lenguaje Java (algo muy parecido al lenguaje C), que
son interpretados por el visualizador, y que permiten realizar páginas
“inteligentes”.
Conectándose a Internet, con un
visualizador Netscape o Explorer, además de ver documentos HTML se puede
recibir y enviar correo electrónico, recibir y enviar NEWS (noticias), visitar
los servidores GOPHER (servidores de ficheros), y acceder a servidores FTP (más
servidores de ficheros) tanto en entrada como en salida, todo ello con el mismo
programa. También, como no, se pueden imprimir los documentos visualizados.
Casi todos suelen ser ” WYSIWYG”.
Sistemas de Búsqueda
En la Web no existe un directorio centralizado.
Para acceder a una página directamente se debe conocer la dirección exacta
donde se encuentra. Pero lo más habitual no es conocer esa dirección exacta,
sino tener una idea del tema en el que se está interesado y sobre el que se
necesite información.
Existen empresas como Yahoo, Altavista,
Olé, Ozú, etc., que han creado diferentes Sistemas de Búqueda, para evitar la
navegación a la deriva.
Estas consisten en un tipo de páginas
Web donde se puede escribir una palabra o una breve referencia que defina la
búsqueda que se quiere realizar. El sistema consulta sus datos y te muestra
enlaces con las páginas Web que contienen la referencia escogida. Existen
diferentes buscadores y cada uno de ellos ha creado su propio directorio. Unos
son más completos, otros más organizados, otros son más exigentes y selectivos
en su información, cada uno tiene características propias, pero todos ellos
ayudan a mantener el rumbo.
¿Qué puede contener una Página Web?
Hemos mencionado el tipo de información
que puede contener una página Web: texto, imagen, sonido, vídeo, e incluso,
mundos 3D y animación.
El usuario no se limita a buscar y
encontrar la información de un modo pasivo, sin intervenir. La mayor innovación
de las páginas Web se traduce en una sola palabra:
Interactividad. Una página Web puede contener
elementos que permiten una comunicación activa entre el usuario e información,
la página responderá a sus acciones.
Por
ejemplo:
- Formularios: a través de los cuales la empresa podrá disponer de un
modo de solicitud de información, un buzón de sugerencias o posibilidad de
realizar subscripciones o pedidos
- Accede y manejar bases de datos de todo tipo: Consultar por
ejemplo, una lista de todos los fondos de inversión en España.
- Participar en los juegos más diversos. Echar una partida de Bingo o
participar en un divertido juego de búsqueda por el ciberespacio.
- Sistemas de Búsquedas: Encontrar las páginas que contienen
información que se necesita en los principales buscadores españoles o
localizar una empresa en las páginas amarillas electrónicas.
Dominio
En el supuesto de estar buscando
información sobre una empresa determinada, el primer impulso sería teclear el
nombre de la empresa seguido del sufijo es o com, los más habituales.
Si se realiza esta acción sólo se encontrará
a la empresa en esa dirección si se dispone de dominio propio, es decir
si la empresa tiene un servidor propio o ha alquilado espacio en un servidor
dedicado a la gestión y mantenimiento de páginas Web. Si no es así, si la
empresa simplemente se encuentra situada en el dominio de otra compañia, será
más difícil de localizar, ya que tendrá una dirección más complicada, difícil
de encontrar y memorizar.
Además, si la empresa tiene dominio
propio, en el caso de que decida cambiar de compañía a la que alquile el
espacio, la dirección se mantiene, ya que el dominio propio pertenece a la
empresa que lo usa y puede instalarse en otro host sin problemas. Si no tiene
dominio propio y decide cambiar de proveedor de Internet, su dirección de
Internet cambiará y tendrá que reflejarlo en su publicidad.
El dominio propio ofrece una imagen más
profesional y competente. Los clientes agradecerán que se les proporcione un
acceso sencillo y consistente a su información.
URLs
Localizador Uniforme de Recursos (URL;
Uniform Resource Locator )es una dirección especial usada por los navegadores
Web, para tener acceso a información en Internet. El URLs especifica el
ordenador en que se hospeda, el directorio, y el nombre del fichero A través de
estas direcciones o URLs vamos a poder conectar los diferentes objetos (no solo
texto), aunque se acceda a ellos a través de diferentes protocolos. Una
cualidad de los URLs es que permiten utilizar los datos ya existentes en la
Internet (Wais, Gofher, ftp) y así es como consigue la Web envolver a la
Internet sencilla y eficazmente
3.2 LA ARQUITECTURA CLIENTE/SERVIDOR
DEL WEB

Cliente-servidor
La arquitectura
cliente-servidor es un modelo de aplicación distribuida en el que las
tareas se reparten entre los proveedores de recursos o servicios, llamados
servidores, y los demandantes, llamados clientes. Un cliente realiza peticiones
a otro programa, el servidor, que le da respuesta.
En esta arquitectura la capacidad de
proceso está repartida entre los clientes y los servidores, aunque son más
importantes las ventajas de tipo organizativo debidas a la centralización de la
gestión de la información y la separación de responsabilidades, lo que facilita
y clarifica el diseño del sistema.
La separación entre clientes y
servidor es una separación de tipo lógico, donde el servidor no se ejecuta
necesariamente sobre una sola máquina ni es necesariamente un sólo programa. b
Una
disposición muy común son los sistemas multicapa en los que el
servidor se descompone en diferentes programas que pueden ser ejecutados por
diferentes computadoras aumentando así el grado de distribución del
sistema.
La arquitectura
cliente-servidor sustituye a la arquitectura monolítica en la
que no hay distribución, tanto a nivel físico como a nivel lógico.
La red cliente-servidor es aquella red
de comunicaciones en la que todos los clientes están conectados a un servidor,
en el que se centralizan los diversos recursos y aplicaciones con que se
cuenta; y que los pone a disposición de los clientes cada vez que estos son solicitados.
Características
- Es quien inicia solicitudes o
peticiones, tienen por tanto un papel activo en la comunicación
(dispositivo maestro o amo).
- Espera y recibe las respuestas del
servidor.
- Por lo general, puede conectarse a
varios servidores a la vez.
- Al contratar un servicio de redes,
se debe tener en cuenta la velocidad de conexión que le otorga al cliente
y el tipo de cable que utiliza , por ejemplo : cable de cobre ronda
entre 1 ms y 50 ms.
Al receptor de la
solicitud enviada por el cliente se conoce como servidor. Sus
características son:
- Al iniciarse esperan a que lleguen las solicitudes de los clientes,
desempeñan entonces un papel pasivo en la comunicación
(dispositivo esclavo).
- Tras la recepción de una solicitud, la procesan y luego envían la
respuesta al cliente.
- Por lo general, aceptan conexiones desde un gran número de clientes
(en ciertos casos el número máximo de peticiones puede estar limitado).
- No es frecuente que interactúen directamente con los usuarios
finales.
3.3 LA ARQUITECTURA MULTICAPA EN EL
WEB. AUMENTO DE LAS FUNCIONALIDADES DE LOS SERVIDORES DEL WEB

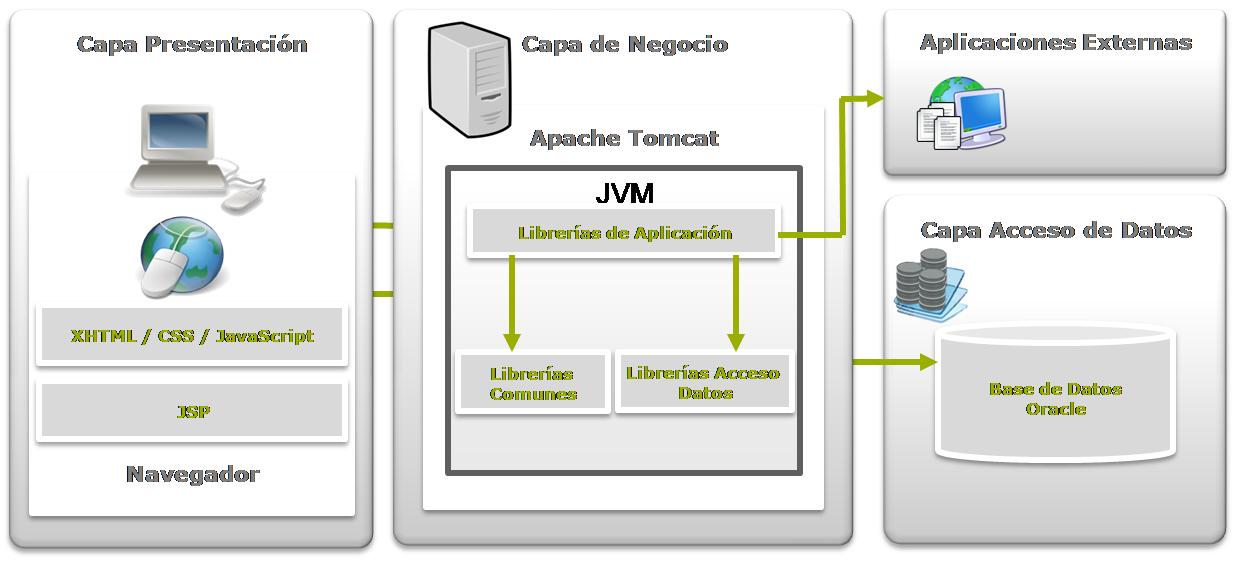{kind=link}
Arquitecturas multi-capas
La arquitectura cliente/servidor
genérica tiene dos tipos de nodos en la red: cliente y servidores.
Consecuentemente, estas arquitecturas genéricas se refieren a veces como
arquitecturas de dos niveles o dos capas.
Algunas redes disponen de tres tipos de
nodos:
- Clientes que interactúan con los usuarios finales.
- Servidores de aplicación que procesan los datos para los clientes.
- Servidores de la base de datos que almacenan los datos para los
servidores de aplicación.
Esta configuración se llama una
arquitectura de tres-capas.
- Ventajas de las arquitecturas
n-capas:
La ventaja fundamental de una
arquitectura n-capas comparado con una arquitectura de dos niveles (o
una tres-capas con una de dos niveles) es que separa hacia fuera el proceso,
eso ocurre para mejorar el balance la carga en los diversos servidores; es más
escalable.
- Desventajas de las arquitecturas
de la n-capas:
§ Pone más carga en la red, debido a una
mayor cantidad de tráfico de la red.
§ Es mucho más difícil programar y probar
el software que en arquitectura de dos niveles porque tienen que
comunicarse más dispositivos para terminar la transacción de un usuario.
§ Centralización del control: los
accesos, recursos y la integridad de los datos son controlados por el servidor
de forma que un programa cliente defectuoso o no autorizado no pueda dañar el
sistema. Esta centralización también facilita la tarea de poner al día datos u
otros recursos.
§ Fácil mantenimiento: al estar
distribuidas las funciones y responsabilidades entre varios ordenadores
independientes, es posible reemplazar, reparar, actualizar, o incluso trasladar
un servidor, mientras que sus clientes no se verán afectados por ese cambio (o
se afectarán mínimamente). Esta independencia de los cambios también se conoce
como encapsulacion.
§ Existen tecnologia, suficientemente
desarrolladas, diseñadas para el paradigma de C/S que aseguran la
seguridad en las transacciones transacciones, la amigabilidad de la
interfaz, y la facilidad de empleo.
§ El paradigma de C/S clásico no tiene la
robustez de una red P2P. Cuando un servidor está caído, las peticiones de los clientes no
pueden ser satisfechas. En la mayor parte de redes P2P, los recursos están generalmente
distribuidos en varios nodos de la red. Aunque algunos salgan o abandonen la
descarga; otros pueden todavía acabar de descargar consiguiendo datos del resto
de los nodos en la red.
Dirección
Los métodos de dirección en ambientes
del servidor de cliente se pueden describir como sigue:
- Dirección del proceso de la
máquina: la dirección se divide como proceso@máquina. Por lo tanto 56@453
indicaría el proceso 56 en la computadora 453.
- Servidor de nombres: los servidores de nombres tienen un índice de todos los nombres y
direcciones de servidores en el dominio relevante.
- Localización de Paquetes: Los mensajes de difusión se
envían a todas las computadoras en el sistema distribuido para determinar
la dirección de la computadora de la destinación.
- Comerciante: Un comerciante es un sistema que pone en un índice todos los
servicios disponibles en un sistema distribuido. Una computadora que
requiere un servicio particular comprobará con el servicio que negocia
para saber si existe la dirección de una computadora que proporciona tal
servicio.
Arquitectura en 2 niveles
La arquitectura en 2 niveles se utiliza
para describir los sistemas cliente/servidor en donde el cliente solicita
recursos y el servidor responde directamente a la solicitud, con sus propios recursos.
Esto significa que el servidor no requiere otra aplicación para proporcionar
parte del servicio.

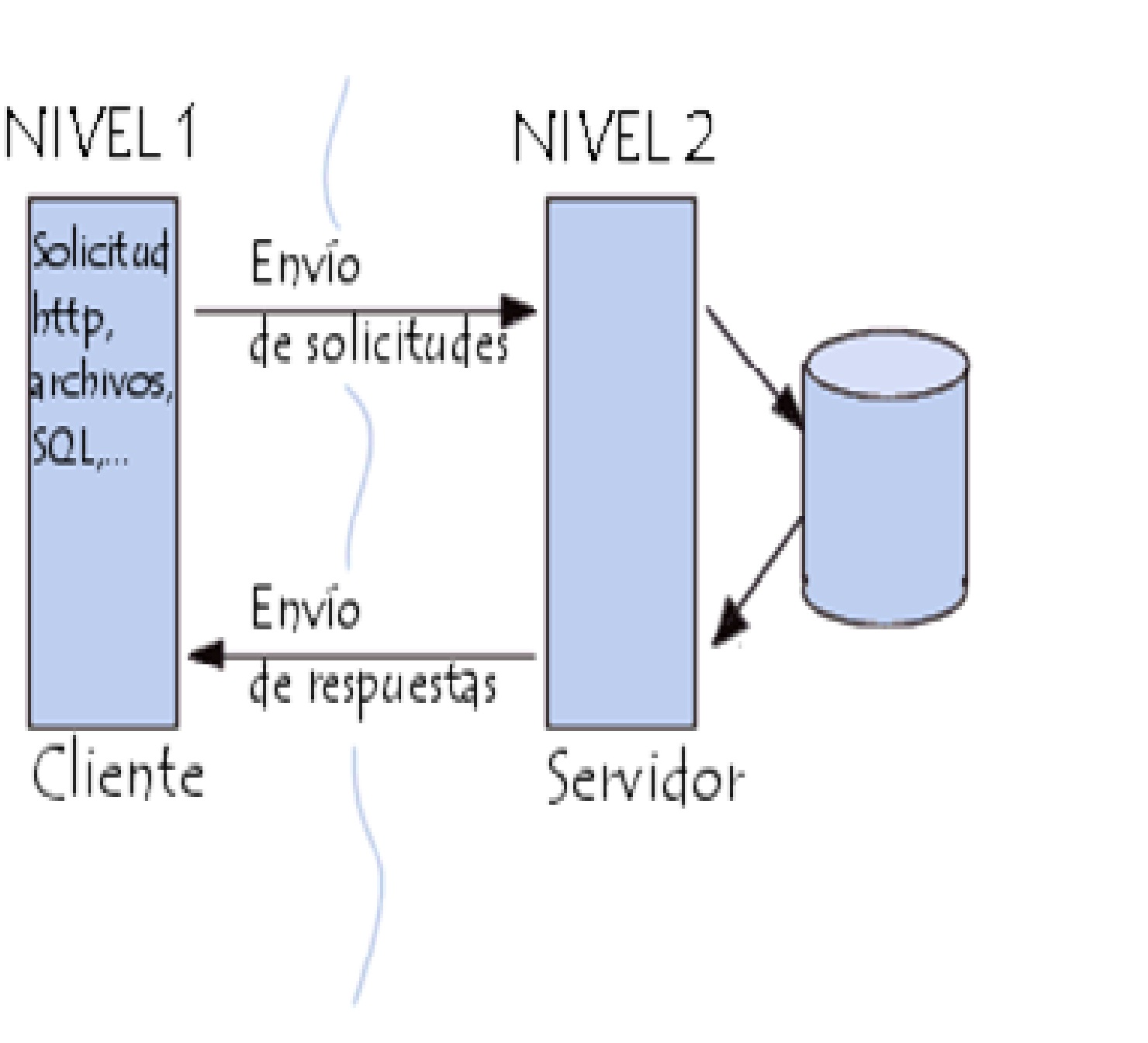{kind=link}
Introducción a la arquitectura en 3
niveles

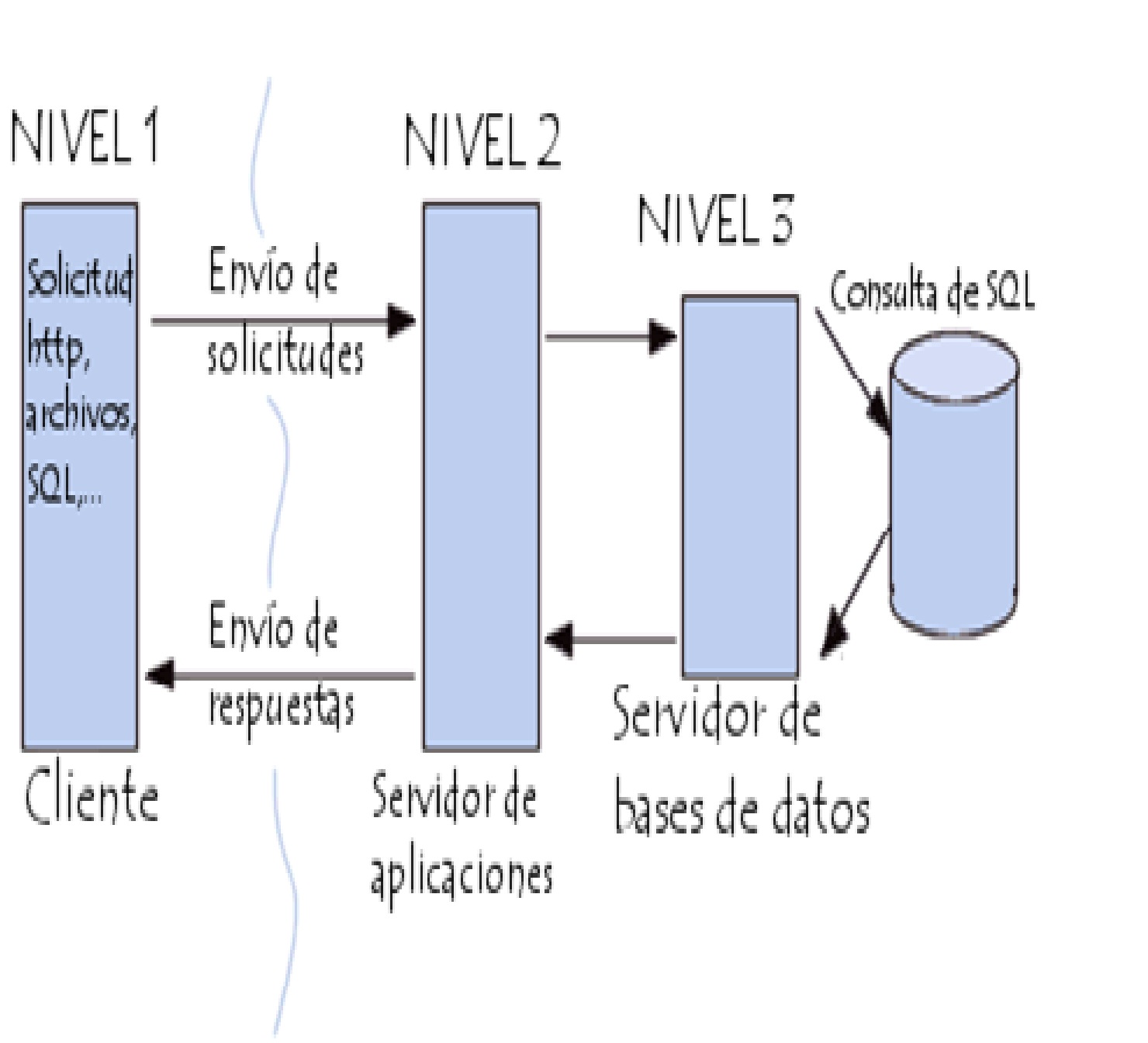{kind=link}
Arquitectura de niveles múltiples

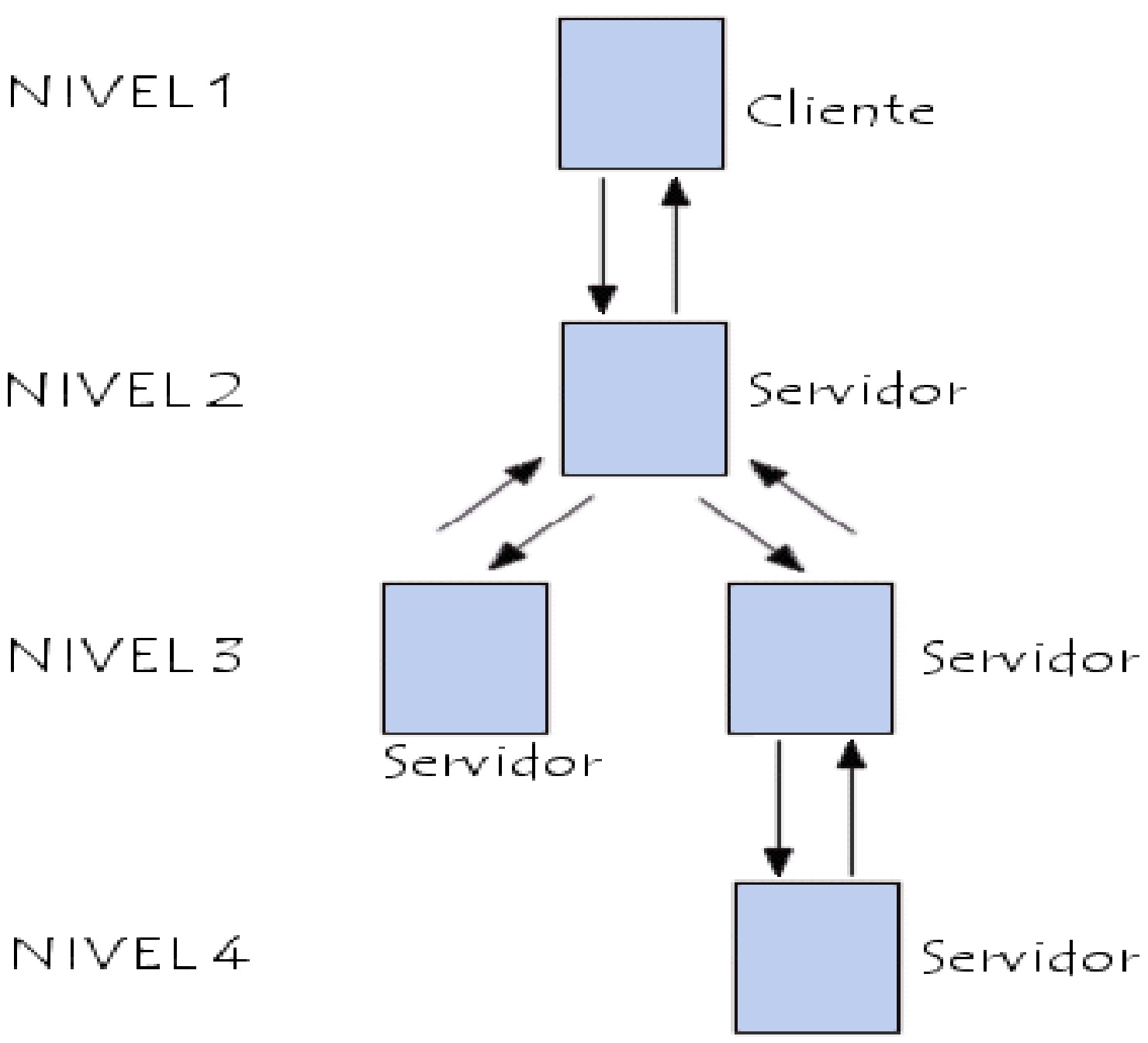{kind=link}
3.4 LA INTERFAZ CGI (COMMON GATEWAY
INTERFACE) Y LAS APLICACIONES QUE USAN ESA ARQUITECTURA

{kind=link}
Interfaz de entrada común ( Common
Gateway Interface,
abreviado CGI) es una importante tecnología de la world wide web que
permite a un cliente. CGI especifica un estandar para transferir datos
entre el cliente y el programa. Es un mecanismo de comunicación entre el
servidor web y una aplicación externa cuyo resultado final de la ejecución son
objetos MIME. Las aplicaciones que se ejecutan en el servidor reciben el nombre
de CGIS.
CGI ha hecho posible la implementación
de funciones nuevas y variadas en las páginas web, de tal manera que esta
interfaz rápidamente se volvió un estándar, siendo implementada en todo tipo de
servidores web.
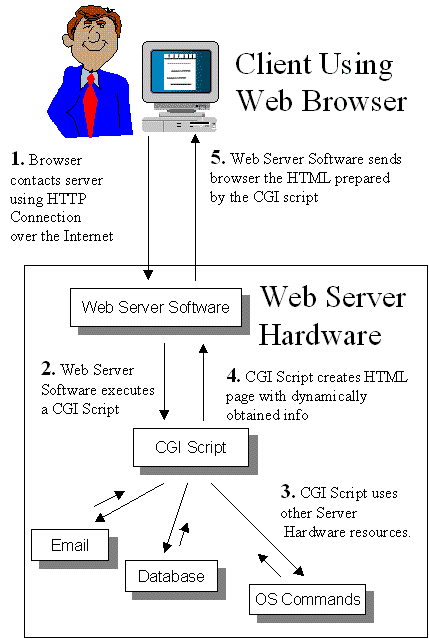
Forma de actuación de CGI
A
continuación se describe la forma de actuación de un CGI de forma esquemática:
1.
En
primera instancia, el servidor recibe una petición (el cliente ha activado un
URL que contiene el CGI), y comprueba si se trata de una invocación de un
CGI.
2.
Posteriormente,
el servidor prepara el entorno para ejecutar la aplicación. Esta información
procede mayoritariamente del cliente.
3.
Seguidamente,
el servidor ejecuta la aplicación, capturando su salida estandar.
4.
A
continuación, la aplicación realiza su función: como consecuencia de su
actividad se va generando un objetoMIME que la aplicación escribe en su
salida estándar.
5.
Finalmente,
cuando la aplicación finaliza, el servidor envía la información producida,
junto con información propia, al cliente, que se encontraba en estado de
espera. Es responsabilidad de la aplicación anunciar el tipo de objeto MIME que
se genera (campo CONTENT_TYPE).
Programación de un CGI
Un programa CGI puede ser escrito en
cualquier lenguaje de programación que produzca un fichero ejecutable. Entre
los lenguajes más habituales se encuentran: C, C++, perl, java, visual basic.
No obstante, debido a que el CGI recibe los parámetros en forma de texto será
útil un lenguaje que permita realizar manipulaciones de las cadenas de
caracteres de una forma sencilla, como por ejemplo Perl. Perl es un lenguaje
interpretado que permite manipulaciones sencillas de ficheros y textos, así
como la extracción y manipulación de cadenas de caracteres, unidas a unas
búsquedas rápidas y fáciles.
Intercambio de información:
Variables de entorno
Variables de entorno que se
intercambian de cliente a CGI:
1. QUERY_STRING: Es la cadena de entrada del CGI
cuando se utiliza el método GET sustituyendo algunos símbolos especiales por
otros. Cada elemento se envía como una pareja Variable=Valor. Si se utiliza el
método POST esta variable de entorno está vacía.
2. CONTENT_TYPE: Tipo MIME de los datos enviados al
CGI mediante POST. Con GET está vacía. Un valor típico para esta variable
es: Application/X-www-form-urlencoded.
3. CONTENT_LENGTH: Longitud en bytes de los datos
enviados al CGI utilizando el método POST. Con GET está vacía.
4. PATH_INFO: Información adicional de la ruta (el
“path”) tal y como llega al servidor en el URL.
5. REQUEST_METHOD: Nombre del método (GET o POST)
utilizado para invocar al CGI.
6. SCRIPT_NAME: Nombre del CGI invocado.
7. SERVER_PORT: Puerto por el que el servidor recibe
la conexión.
8. SERVER_PROTOCOL: Nombre y versión del protocolo en
uso. (Ej.: HTTP/1.0 o 1.1)
Variables de entorno que se
intercambian de servidor a CGI:
1. SERVER_SOFTWARE: Nombre y versión del software
servidor de www.
2. SERVER_NAME: Nombre del servidor.
3. GATEWAY_INTERFACE: Nombre y versión de la interfaz de
comunicación entre servidor y aplicaciones CGI/1.12
4. Contador
de accesos:
Cuenta el número de veces que se ha solicitado una página determinada. Se
guarda el valor en un fichero. Cada vez que se invoca se incrementa, para su
posterior visualización.
5. Buscador: Localiza páginas que contengan los
términos especificados. Utiliza una tabla que enumera las palabras y para cada
una especifica las páginas dónde se encuentra.
6. Correo: Obtiene información estructurada del
usuario.
7. Contribuciones: Permite añadir enlaces o anotaciones
a una página, indicando la procedencia de la adición.
8. Estadísticas
de uso:
Presenta información sobre los acontecimientos producidos en el servidor de WWW.
El servidor mantiene un registro (log) de los acontecimientos que se han
producido.
9. Administración
remota del servidor:
Permite interactuar con el servidor desde WWW. Invoca los programas que
controlan o modifican el comportamiento del servidor.
10.
Situación inicial: El cliente solicita la invocación
de un CGI, bien de manera involuntaria (se envía únicamente información de
cabecera) o bien de forma explícita (formulario). En el formulario hay parejas
del tipo variable=valor. El método de http especificado en el formulario puede
ser GET o POST.
En el servidor en cambio, el fichero de configuración especifica un directorio cgi-bin con capacidad para ejecutar programas. Puede haber otros ficheros y otros programas a los que puede acceder tanto el servidor como sus CGIs.
En el servidor en cambio, el fichero de configuración especifica un directorio cgi-bin con capacidad para ejecutar programas. Puede haber otros ficheros y otros programas a los que puede acceder tanto el servidor como sus CGIs.
11.
El cliente pulsa el botón de tipo
SUBMIT en el formulario: Dependiendo
del método se construye un mensaje que contiene la información del formulario
en la cabecera (para GET) o en el cuerpo del mensaje (para POST). El mensaje se
envía al servidor, añadiendo información propia del cliente que el propio
navegador conoce. El cliente queda a la espera de recibir un objeto MIME como
respuesta del servidor.
12.
El servidor recibe el mensaje de
petición o pone en marcha el programa CGI: El servidor compara la
información del mensaje con la que conoce de su fichero de configuración,
determinando así la validez de la petición. En realidad el servidor se
pregunta: ¿Existe esta URL? ¿Se tienen todos los permisos?.
Prepara el entorno añadiendo información propia a la comunicada por el navegador del cliente. Si es GET, la información procedente del formulario (parejas variable=valor) se definen en QUERY_STRING. El servidor posteriormente pone en funcionamiento el CGI. Si se trata de POST, la información se coloca en la entrada estándar del CGI. Finalmente se inicia la ejecución del CGI y el servidor espera a que ésta acabe.
Prepara el entorno añadiendo información propia a la comunicada por el navegador del cliente. Si es GET, la información procedente del formulario (parejas variable=valor) se definen en QUERY_STRING. El servidor posteriormente pone en funcionamiento el CGI. Si se trata de POST, la información se coloca en la entrada estándar del CGI. Finalmente se inicia la ejecución del CGI y el servidor espera a que ésta acabe.
13.
Ejecución del CGI: El CGI accede a las variables de
entorno. Comprueba o adapta el funcionamiento según el método GET o POST
establecido en REQUEST_METHOD: si se tratara de GET, la información estará en
QUERY_STRING, mientras que si se trata de POST, se tomará la entrada estándar.
Tipos
habituales de CGIs
Escenario
de activación de un CGI
Se construye un objeto MIME que se
enviará al cliente. La primera escritura deberá anunciar el tipo de objeto:
CONTENT_TYPE: tipo/subtipo.
1. El
servidor vuelve al trabajo: El
servidor añade a su respuesta del CGI una cabecera indicando su tamaño
(CONTENT_LENGTH).
2. El
cliente recibe la respuesta: Interpretación de la respuesta.
Visualización con el navegador
Tradicionalmente el cliente (navegador)
web accede a páginas ya construidas y estáticas. Para que el usuario pueda
interactuar con ella y que se puedan construir páginas en función de sus
necesidades, se puede optar por dos alternativas:
- Programas ejecutados en el cliente, como JavaScript.
- Aplicaciones ejecutadas en el servidor y que devuelven páginas
HTML, gráficos, etc. como pueden ser los formularios (páginas) o los
contadores (imágenes).
La interfaz CGI es un mecanismo que
permite la invocación de una aplicación ejecutada en el servidor desde una
página HTML que se está viendo en un cliente. Tradicionalmente la aplicación
devolverá una página HTML al cliente o recogerá datos que el cliente le envió.
Para ejecutar una aplicación CGI se
puede hacer de varias maneras:
- Accediendo a su URL: http://aqui.es/cgi-bin/prog.pl=param1=valor¶m2=valor
- Desde una página HTML, de varias formas:
§ Desde una imagen:
<img src=”http://aqui.es/cgi-bin/contador.pl?f=cnt.dat”>
<img src=”http://aqui.es/cgi-bin/contador.pl?f=cnt.dat”>
§ Desde un formulario:
<form method=”POST” action=”http://aqui.es/cgi-bin/prueba.pl”>
<form method=”POST” action=”http://aqui.es/cgi-bin/prueba.pl”>
§ Un enlace al CGI:
<a href=”http://aqui.es/cgi-bin/prog.pl?variable=valor”>Enlace a CGI</a>
<a href=”http://aqui.es/cgi-bin/prog.pl?variable=valor”>Enlace a CGI</a>
A las aplicaciones CGI se le pueden
pasar parámetros de dos formas distintas llamadas métodos, que se obtiene de la variable de
entorno REQUEST_METHOD:
- Método GET: Los parámetros forman parte de la URL, y la aplicación los lee
como variables de entorno. Se obtienen de la variable de entorno QUERY_STRING, y la longitud de la cadena de parámetros, deCONTENT_LENGTH.
http://aqui.es/cgi-bin/prog.pl=param1=valorA¶m2=valorB, donde los parámetros serían param1 y param2, y sus correspondientes valores, valorA y valorB - Método POST: Los parámetros no forman parte de la URL y se envían formando
parte de la petición del protocolo http. La aplicación CGI leerá los
parámetros por la entrada estándar.
El método utilizado,
La aplicación CGI devuelve el resultado
por la salida estándar, y la primera línea que envíe al cliente será la que
determine el tipo de resultado:
- Página
HTML: print “Content-type: text/html\n\n”
- Página de texto simple: print “Content-type: text/plain\n\n”
- Gráfico: print
“Content-type: image/gif\n\n”
3.5 FORMALISMOS PARA LA VALIDEZ DE LA
ARQUITECTURA DEL WEB

{kind=link}
Con Arquitectura de la Información
Web (AI)
nos referimos a la disciplina y arte encargada del estudio, análisis,
organización, disposición y estructuración de la información en espacios de
información, en este caso específicamente, Páginas Web.
La metodología para construir una casa
no es muy diferente de la que se requiere para hacer un sitio web. En nuestros
hogares los picaportes y las manijas de las puertas están a un metro del suelo
porque esa es la altura que se encuentran nuestras manos y es más cómodo
alcanzarlas. De igual forma, en la web, las aplicaciones deben estar diseñadas
sobre la base de las necesidades de las personas que van a utilizarlas.
Para construir una casa o un edificio
se requiere un profundo conocimiento de las tecnologías aplicadas: las
propiedades estructurales de los materiales, mecánica, electricidad, redes de
agua, etc; Así mismo, en el desarrollo web se requiere conocimientos de programación
y estructura de bases de datos, servidores, redes, protocolo TCP/IP, lenguaje
HTM, componentes de backup, seguridad y muchos otros. la arquitectura Web
supone un reto cada vez mayor para las empresas que buscan sacar un mayor
provecho y aumentar la rentabilidad de su inversión en Internet.
Con el objetivo de que la asimilación
de contenidos del internauta sea eficiente y efectivo, y para que el sitio sea
accesible y usable, en DesigNet nos preocupamos de:
• La definición del público objetivo y
los estudios de la audiencia.
• La realización de análisis
competitivos.
• El diseño de la interacción.
• El diseño de la navegación, esquemas
de organización y facetación de los contenidos
• El etiquetado o rotulado de los
contenidos para acceder a la información.
• La usabilidad.
• La accesibilidad
• El feedback del resultado y los
procesos de reingeniería del sitio
En la actualidad todavía hay quienes no
le dan importancia a este tema y desarrollan sitios sin una estructura
significativa. En DesingnNet en cambio, nos preocupamos por hacer un sitio que
permita al usuario navegar fácil e intuitivamente por las distintas secciones,
sin perder la orientación, con una presentación gráfica que sea visualmente
atractiva y agradable, de fácil lectura, limpia y moderna.
El principal objetivo de la
arquitectura Web es resolver las necesidades específicas del negocio:
- Venta de productos.
- Servicios online.
- Satisfacción de las necesidades de los potenciales clientes.
Continuando con la comparativa, los
detalles de un edificio son equiparables al diseño que requiere una página web,
para lo cual es recomendable acudir a profesionales especializados
específicamente en las siguientes áreas:
- Lenguajes de programación.
- Bases de datos.
Es fundamental destacar que la formación y experiencia que
requiere la puesta en marcha de las acciones englobadas en la arquitectura Web
requiere de profesionales en constante formación, dinámicos y en continua
evolución, con el valor agregado de contar con la constancia del objetivo
final: La satisfacción de los usuarios que utilizarán el portal Web.
3.6 ESQUEMAS ACTUALES QUE HACEN
USO DE LA ARQUITECTURA DEL CGI

{kind=link}
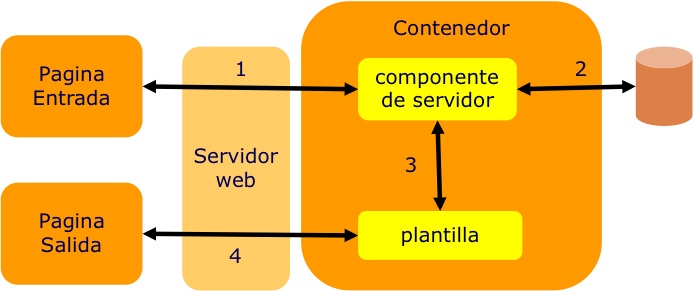
DISTRIBUCIÓN DE APLICACIONES
VIA SISTEMA CLIENTE-SERVIDOR
Presentación del proyecto ATF
El sistema telemático que aquí se presenta (ATF o Asistente
Telemático a la Formación) es un desarrollo de Divisa Informática S.A., empresa
de Ingeniería en Informática y Telecomunicaciones ubicada en Castilla y León,
en el que colabora la Universidad de Valladolid a través de la Escuela Técnica
Superior de Ingenieros de Telecomunicación de Valladolid.
Arquitectura del sistema ATF. Servidor Educativo
La arquitectura definida, sigue la estructura tradicional cliente
servidor, aunque esta se encuentra modificada de forma parcial: donde el
Servidor Educativo es el compendio de todos los servidores asociados,
localizados en el proveedor de servicios telemáticos. Un requisito necesario a
la hora de diseñar la arquitectura, fue el considerar una distribución de estos
en diferentes máquinas, tal que se permita su futura escalabilidad.
Distribuido Educativo puede ser
esta:
•Servidor Web •Base de Datos Relacional •Servidor SMTP •Servidor
POP3 •Servidor News •Servidor FTP anónimo
La función del servidor Web, es actuar a modo de Servidor de
Aplicación. El cliente, accede a través del servidor Web a los contenidos del
curso y otros módulos adicionales bajo descarga selectiva. También actúa de
interfaz de acceso a la base de datos aunque el cliente pueda consultar
directamente la base de datos con el fin de obtener cierta información
administrativa (por ejemplo para una autoconfiguración selectiva de la
herramienta del cliente)
El cliente del sistema ATF
El cliente, denominado Aula Virtual y desarrollado para sistemas
operativos Windows95 y NT, realiza las funciones fundamentales de un navegador
tradicional, siendo la interfaz personal de trabajo del alumno y profesor.
Como aspecto favorable a la interfaz, el alumno nunca asocia los
contenidos a direcciones de formato URL (o cualquier otro formato no
entendible). De una forma más pedagógica, los contenidos se pueden relacionan
con frases breves (herramienta de favoritos) o a textos personales más largos
(herramienta de notas) creados por el mismo alumno.
La interfaz también dispone de una herramienta de correo. Otra
herramienta interesante desarrollada fue el cliente de news, aquí bajo la
denominación de tablón de anuncios. Estos dos clientes permiten la comunicación
directa entre los participantes del curso y su tutor o tutores. Al implementar
estas herramientas, se buscó la facilidad de uso. No son herramientas avanzadas
o complejas, por contra, son altamente intuitivas en su manejo. El usuario
muchas veces utiliza un porcentaje muy limitado de la funcionalidad de su
correo, ya que el esfuerzo asociado al aprendizaje siempre es alto. Un objetivo
que guía el desarrollo es no desmotivar nunca al usuario, obligándole aprender
a utilizar un entorno complejo, más aún si no se encuentra familiarizado con
las redes telemáticas. También, como se advierte en la figura, el atractivo
visual se consideró como un elemento importante, que incita al usuario, y lo
introduce en el entorno ficticio del aula.
La interfaz de cliente incorpora otras herramientas importantes:
Aquellas asociadas al acceso al curso y su gestión.
Junto a estas, se dispone de la posibilidad de realizar los
exámenes propuestos por el tutor o acceder a los eventos definidos por este
(por ejemplo, avisos de clases presenciales). Los eventos se definen como
aquellos hechos o noticias de especial relevancia que emitidos por el profesor,
deben ocupar un papel diferenciado del resto de noticias del tablón.
Sin embargo, el diseño de ATF no busca que su interfaz cliente se
restrinja al aula virtual desarrollado. No se pensó como un desarrollo cerrado.
La interfaz puede estar constituida por cualquier navegador comercial. De esta
forma, los servicios ofrecidos por el sistema, pueden ser disfrutados por
usuarios (al menos en su mayor parte) que no dispongan del cliente del Aula
Virtual. El Aula Virtual, no obstante, ofrece una normalización de acceso al
sistema y a los cursos educativos, junto con el uso de las funcionalidades
ofrecidas del sistema ATF.
PROCESAMIENTO PARALELO DE
APLICACIONES
LIBRERIA PPL
(PARALLEL PROGRAMMING LIBRARY)
PROTOCOLOS DE APLICACION STANDARD Y NO STANDARD
Cualquier programador que haga uso de la librería de funciones
para la implementación de una aplicación que realice su labor en paralelo
tendrá que crear dos programas o procesos distintos :
El servidor, encargado de implementar la función de proceso sobre
un conjunto o zona de datos con una estructura concreta.
El cliente, encargado de la interacción con el usuario y de
controlar la operación de los servidores.
Para coordinar la ejecución de los procesos cliente y servidor es
necesario establecer un protocolo de comunicación entre ambos, es decir un
serie de normas que han de ser conocidas por los dos procesos y que han de ser
cumplimentadas para que una solicitud de servicio pueda llevarse a cabo de
forma correcta. Esto es lo que se conoce como Protocolo de Aplicación.
El protocolo TCP/IP incluye muchos protocolos de aplicación, y
diariamente aparecen nuevos protocolos de aplicación. De hecho, cada vez que un
programador desarrolla un programa distribuido que emplea el TCP/IP para
comunicar los procesos participantes, diseña un nuevo protocolo de aplicación.
Existe un conjunto de protocolos de aplicación que han sido
documentados en RFC y adoptados como parte oficial del protocolo TCP/IP. A
tales protocolos se les denomina protocolos de aplicación standard. Otros
protocolos, ideados por los programadores de aplicaciones para su uso privado,
se les conoce como protocolos de aplicación no standard.
Ejemplos de protocolos de aplicación standard son el FTP (File
Transfer Protocol), login remoto (TELNET) y correo electrónico (E-MAIL). La
sesión remota (remote login) es una de las aplicaciones TCP/IP más populares.
ESQUEMA DE FUNCIONAMIENTO DEL
SERVIDOR
El proceso servidor es el encargado de llevar a cabo el
procesamiento de los datos remitidos por el proceso cliente. Su función es
quedar en espera de peticiones de servicio y atenderlas conforme le van
llegando.
Cuando el proceso servidor es ejecutado en uno de los hosts o
equipos de la red, realiza la siguientes tareas de inicialización :
•Averigua la dirección IP, así como el nombre (si es que hay
alguno definido) del host (anfitrión) en el cual se está ejecutando. •Realiza
una llamada al sistema para obtener el descriptor de socket a través de cual
recibirá y transmitirá las tramas de bytes. •Forma la dirección de red en la
cual va a escuchar peticiones de servicio. Dicha dirección está constituida por
la dirección IP del host y el puerto en el cual va a atender solicitudes de
servicio. •Se bloquea en espera de peticiones de servicio.
SERVICIOS PPL STANDARD
Los procesos cliente y servidor definidos en la librería PPL
utilizan un protocolo de aplicación, lo llamaremos protocolo PPL, el cual
define los servicios más comunes que van a ser empleados por las aplicaciones
paralelas que van a poder ser desarrolladas con PPL. A estos servicios
predefinidos se los denominaremos Servicios PPL Standard. El programador que
haga uso de la librería PPL es libre de añadir cuantos servicios adicionales
sean necesarios para la aplicación que esté desarrollando, del mismo modo puede
modificar los servicios predefinidos para adaptarlos a sus necesidades. Veamos
detalladamente cada uno de los servicios predefinidos por el protocolo PPL:
SERVICIO PING
No se puede definir como un auténtico servicio, ya que el servidor
no lleva a cabo ninguna labor de proceso o transferencia de datos. Es empleado
por el cliente cuando se encuentra examinando la red en busca de servidores
para saber si en la dirección IP que está siendo examinada se encuentra algún
proceso servidor activo.
SERVICIO
INICIO_PROCESO
Este servicio indica al servidor que aplique la función de proceso
sobre el conjunto de datos o partición que previamente tiene que haberle
transmitido el cliente.
El cliente suele mantener una lista con las direcciones de red de
los servidores activos. Una vez enviada la partición a cada uno de los
servidores se puede emplear la fución de librería start_proces(struct t_host*
lista_servers) la cual se encarga de iniciar el proceso de ejecución en cada
uno de los servidores de la lista que recibe como parámetro.
Protocolo INICIO_PROCESO.
El cliente compone y manda la siguiente trama al servidor para
indicarle el servicio de proceso de datos:
Recibida la trama de petición de servicio, el servidor genera un
proceso hijo que se encarga de llevar a cabo la labor de proceso. Concluido el
proceso de datos es el propio hijo el encargado de componer la siguiente trama
de respuesta que indica al cliente la conclusión del proceso de la zona de
datos y, por lo tanto, la disponibilidad para transmitir los resultados.
Una vez transmitida la trama de solicitud de proceso de
datos, el cliente queda en espera de la trama que indica el fin del proceso. Es
conveniente que el cliente establezca un timeout con el tiempo de proceso
estimado para evitar que espere eternamente si, por ejemplo, el servidor cae a
mitad de proceso o merma considerablemente su velocidad de proceso.
SERVICIO GET_DATA
Este servicio es empleado por el cliente para obtener los
resultado del procesamiento llevado a cabo por el servidor sobre una zona de
datos previamente transmitida por el cliente al servidor.
Protocolo GET_DATA.
El cliente compone una trama en cuya cabecera se indica al
servidor que desea el servicio GET _DATA.
Si no hay nada que lo impida, el servidor responde al cliente
con la siguiente trama en la cual le indica que se va a iniciar la
transmisión de bytes, así como la cantidad de bytes a transferir.
Acto seguido pasa a transmitir los bytes solicitados al cliente.
Para llevar a cabo la transferencia se sirve de la función PPL envia_bytes(int
sfd, char* buf, int nbytes), la cual se encarga de enviar, a través del socket
sfd la cantidad de bytes nbytes apuntada por el puntero buf. Por su parte el
cliente se sirve de la función recibe_bytes(int sfd, char* buf, int nbytes),
para recibir los bytes solicitados.
SERVICIO STATUS
El cliente solicita este servicio del servidor cuando desea
averiguar el estado en el cual se encuentra el servidor (procesando, libre, ….)
Protocolo STATUS.
El proceso cliente compone una trama con la siguiente
estructura :
A continuación pasa a establecer conexión con el servidor
(connect_server).
Establecida la conexión, el cliente pasa a transmitir al servidor
la trama anteriormente expuesta. El servidor analiza el servicio solicitado,
STATUS en este caso, y compone una trama de respuesta con el siguiente
formato :
El servidor almacena su estado en una variable almacenada en
memoria compartida (para que pueda ser modificada por procesos hijo). Este
servicio lo único que hace es retornar el valor de dicha variable al cliente
que inicio la solicitud.
Este servicio puede ser de utilidad para, concluido un tiempo de
espera, solicitar el estado del servidor para saber si aún está operativo o ha
dejado de funcionar.
3.7 ESQUEMAS
PROPIETARIOS PARA EL DESPLIEGUE DE APLICACIONES EN EL WEB

{kind=link}
Intercepting Filter
Contexto
El mecanismo de manejo de peticiones de la capa de
presentación recibe muchos tipos diferentes de peticiones, cada uno de los
cuales requiere varios tipos de procesamiento. Algunas peticiones simplemente
requieren su reenvio al componente manejador apropiado, mientras que otras
peticiones deben ser modificadas, auditadas, o descomprimidas antes de su
procesamiento posterior.
Causas
Procesamiento común, como un chequeo del esquema de codificación
de datos o la información de login de cada petición, completo por cada
petición.
- Se desea la centralización de la lógica común.
- Se debería facilitar la adición o eliminación de
sevicios sin afectar a los componentes existentes, para que se puedan
utilizar en gran variedad de combinaciones, como
§ Logging y autentificación.
§ Depuración y transformación de la salida para un cliente
específico
§ Descomprensión y conversión del esquema de codificación de
la entrada.
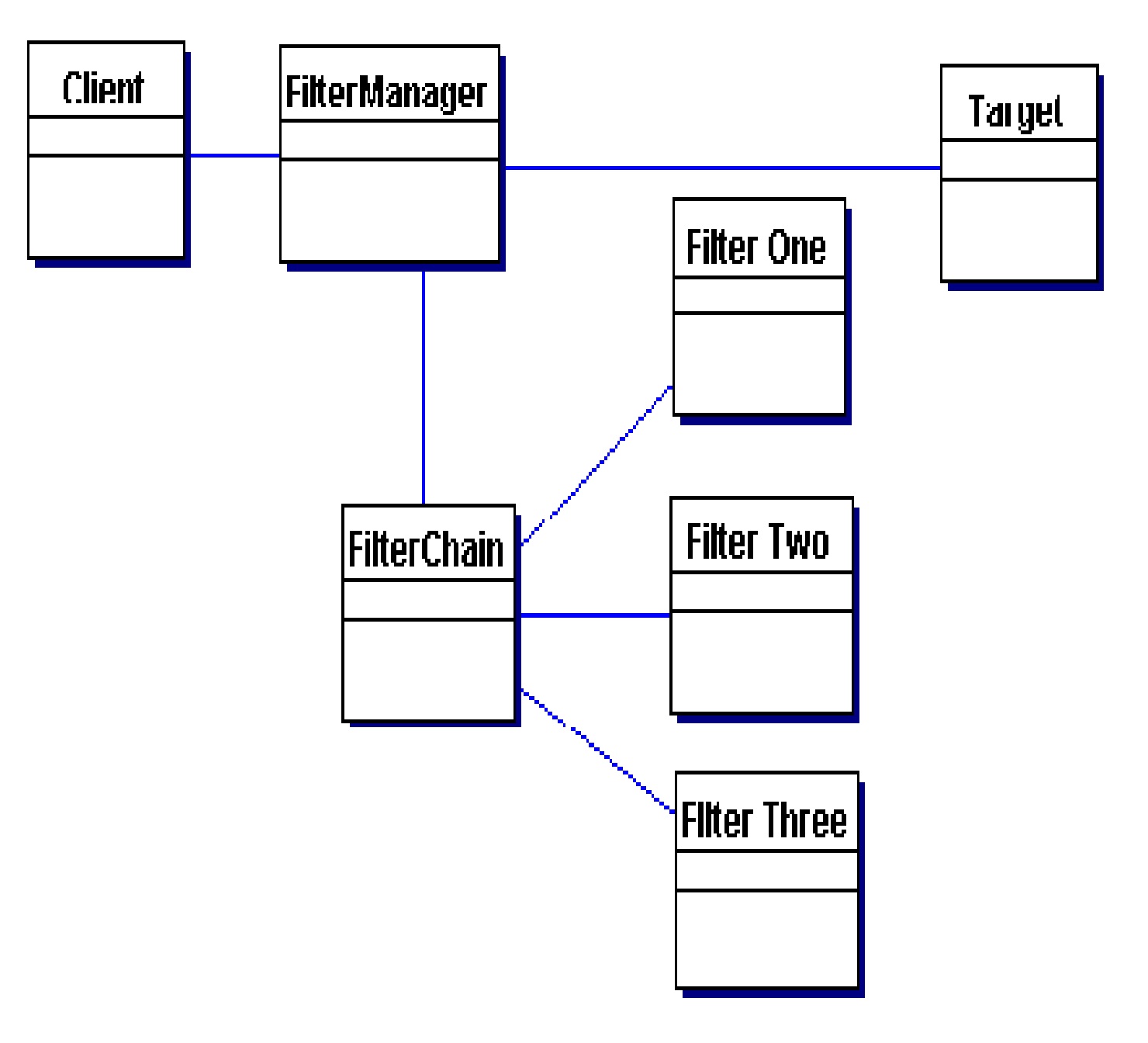
Estructura
La siguiente figura representa el diagrama de clases del
patrón Intercepting Filter.

{kind=link}
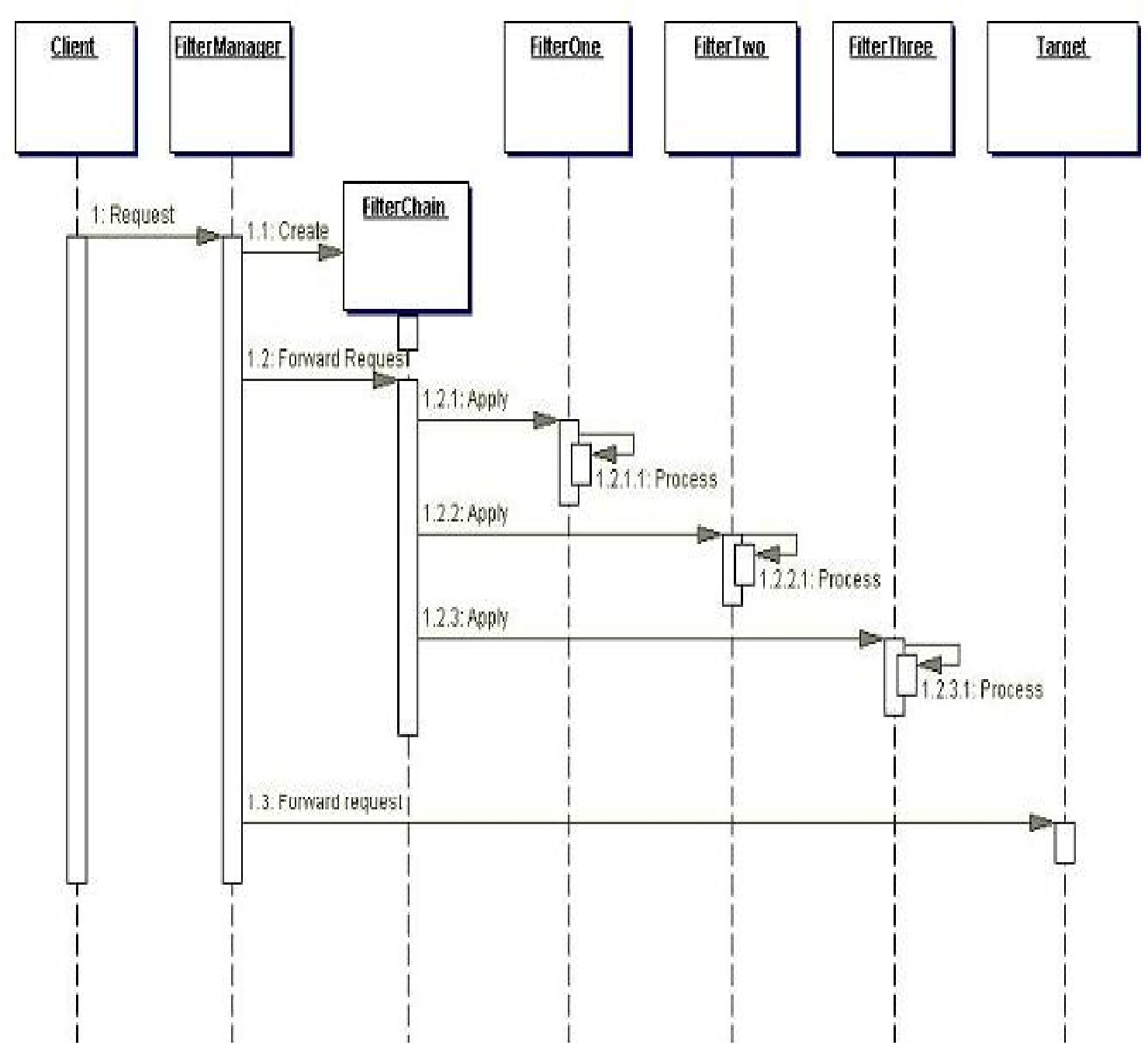
Participantes y Responsabilidades
La siguiente figura representa el diagrama de la secuencia del
patrón Intercepting
Filter.

{kind=link}
FilterManager
El FilterManager maneja
el procesamiento de filtros. Crea el FilterChain con los filtros
apropiados, en el orden correcto e inicia el procesamiento.
FilterChain
El FilterChain es
una collection ordenada
de filtros indenpendientes.
FilterOne, FilterTwo, FilterThree
Estos son los filtros individuales que son mapeados a un objetivo.
El FilterChain coordina
su procesamiento.
Target
El Target es
el recurso que el cliente ha solicitado.
Estrategias
Custom Filter
El filtro se implementa mediante una estrategia personalizada
definida por el desarrollador. Esto es menos flexible y menos poderoso que la
preferida Estrategia de Filtro Estándar que veremos en la siguiente sección y
que sólo está disponible en contenedores que soporten la especificación servlet
2.3. La estrategia de filtro personalizado es menos poderosa porque no puede
proporcionar una envoltura para los objetos request y response de
una forma estándar y portable. Además, el objeto request no se puede
modificar, y se debe introducir alguna suerte de mecanismo de buffer si los
filtros son para controlar los streams de salida. Para implementar esta
estrategia, el desarrollador podría utilizar el patrón Decorator [GoF]
para envolver los filtros alrededor de la lógica principal del procesamiento de
la petición. Por ejemplo, podría haber un filtro de depuración que envuelva un
filtro de autentificación. Los siguientes fragmentos de código muestran como se
podrían crear estos mecanismos de forma programátia:
DebuggingFilter:
public class DebuggingFilter implements Processor {
private Processor target;
public DebuggingFilter(Processor myTarget) {
target = myTarget;
}
public void execute(ServletRequest req,
ServletResponse res) throws IOException,
ServletException {
//Do some filter processing here, such as
// displaying request parameters
target.execute(req, res);
}
}
CoreProcessor:
public class CoreProcessor implements Processor {
private Processor target;
public CoreProcessor() {
this(null);
}
public CoreProcessor(Processor myTarget) {
target = myTarget;
}
public void execute(ServletRequest req,
ServletResponse res) throws IOException,
ServletException {
//Do core processing here
}
}
En el controlador servlet, hemos delegado en un método
llamado processRequest para
manejar las peticiones entrantes:
public void processRequest(ServletRequest req,
ServletResponse res)
throws IOException, ServletException {
Processor processors = new DebuggingFilter(
new AuthenticationFilter(new CoreProcessor()));
processors.execute(req, res);
//Then dispatch to next resource, which is probably
// the View to display
dispatcher.dispatch(req, res);
}
Sólo para propósitos de ejemplo, imagina que cada componente de
procesamiento escribe en la salida estándar cuando se ejecuta. El siguiente
ejemplo muestra la posible salida de la ejecución:
Debugging filter preprocessing completed...
Authentication filter processing completed...
Core processing completed...
Debugging filter post-processing completed...
Se ejecuta una cadena de procesadores en orden. Cada procesador,
excepto el último de la cadena, se considera un filtro. En el componente
procesador final es donde se encapsula el procesamiento principal que queremos
completar para cada petición. Con este diseño, necesitaremos cambiar el código
de la clase CoreProcessor, así
como cualquier clase de filtro, cuando querramos modificar la forma de manejar
las peticiones.

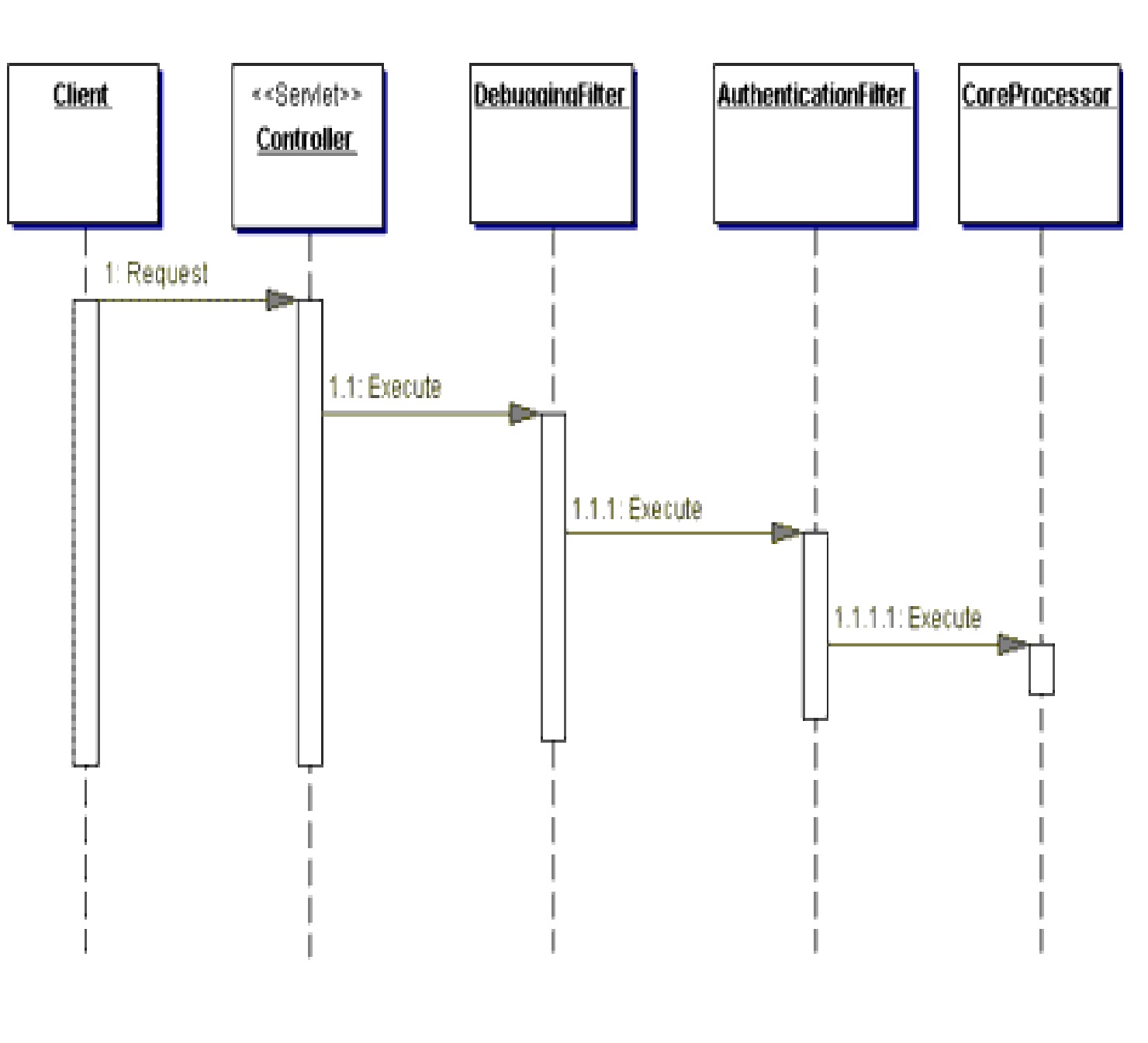{kind=link}
Observa que cuando usamos una implementación de Decorator, cada
filtro invoca directamente al siguiente filtro, aunque usando un interface
genérico. De forma alternativa, esta estrategia se puede implementar utilizando
un FilterManager y
un FilterChain. En
este caso, estos componentes manejan el procesamiento de los filtros y los
filtros individuales no se comunican con ningún otro filtro directamente. Este
diseño se aproxima al de una implementación compatible con Servlet 2.3, aunque
aún así es una estrategia personalizada. En el primero de los siguientes
listado veremos la clase FilterManager que crea un objetoFilterChain.
public class FilterManager {
public void processFilter(Filter target,
javax.servlet.http.HttpServletRequest request,
javax.servlet.http.HttpServletResponse response)
throws javax.servlet.ServletException,
java.io.IOException {
FilterChain filterChain = new FilterChain();
// The filter manager builds the filter chain here
// if necessary
// Pipe request through Filter Chain
filterChain.processFilter(request, response);
//process target resource
target.execute(request, response);
}
}
El FilterChain añade
filtros a la cadena en el orden apropiado (por brevedad lo hemos hecho en el
constructor, pero normalmente se haría en el lugar del comentario), procesa los
filtros, y finalmente procesa el recurso objetivo:
public class FilterChain {
// filter chain
private Vector myFilters = new Vector();
// Creates new FilterChain
public FilterChain() {
// plug-in default filter services for example
// only. This would typically be done in the
// FilterManager, but is done here for example
// purposes
addFilter(new DebugFilter());
addFilter(new LoginFilter());
addFilter(new AuditFilter());
}
public void processFilter(
javax.servlet.http.HttpServletRequest request,
javax.servlet.http.HttpServletResponse response)
throws javax.servlet.ServletException,
java.io.IOException {
Filter filter;
// apply filters
Iterator filters = myFilters.iterator();
while (filters.hasNext())
{
filter = (Filter)filters.next();
// pass request & response through various
// filters
filter.execute(request, response);
}
}
public void addFilter(Filter filter) {
myFilters.add(filter);
}
}
En la siguiente figura podemos ver el diagrama de secuencia de
este código:

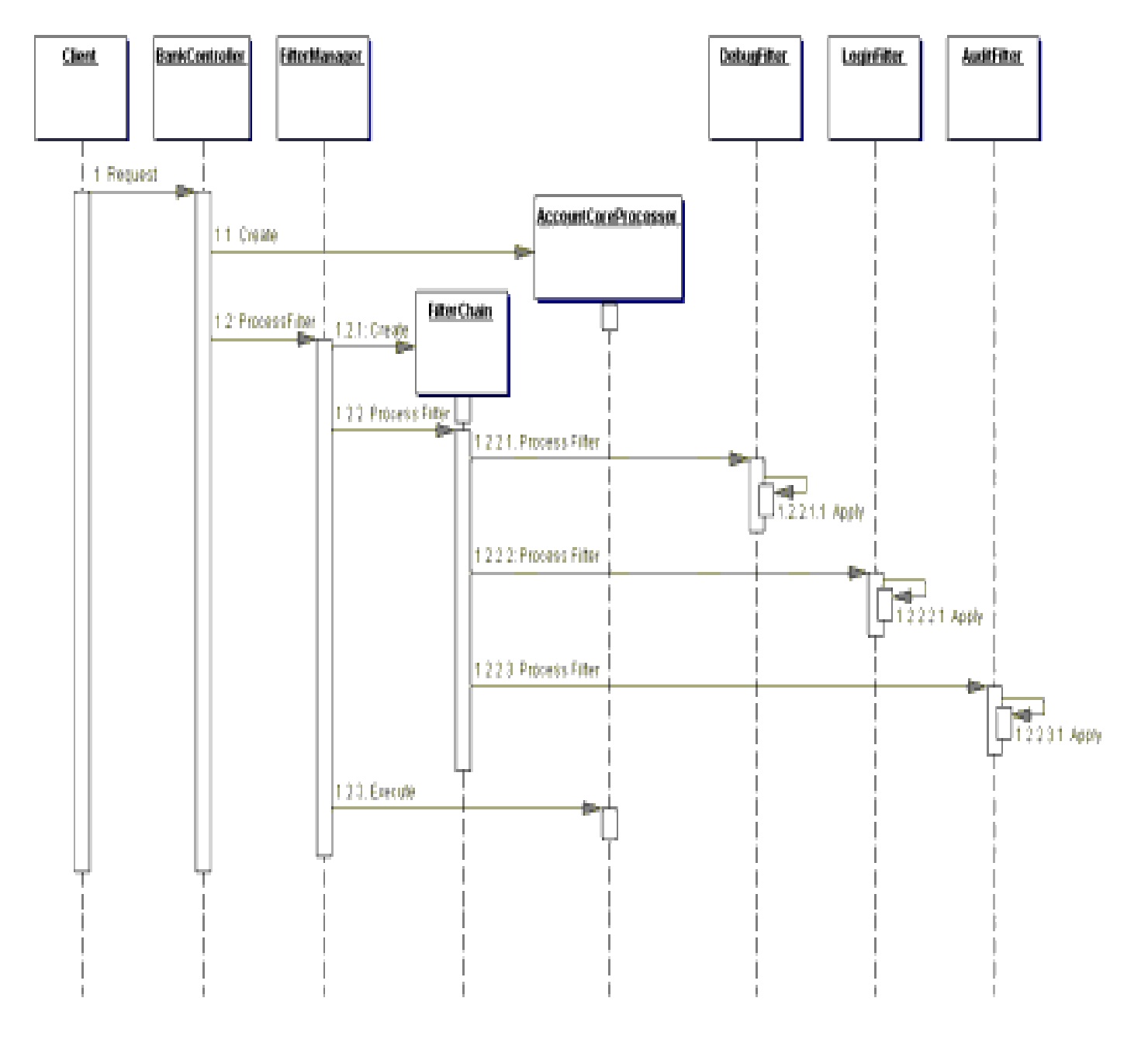{kind=link}
Esta estrategia no nos permite crear filtros que sean tan
flexibles y poderosos como nos gustaría. Por una cosa, los filtros se añade y
eliminan programáticamente. Aunque podríamos escribir un mecanismo propietario
para manejar la adición y eliminación de filtros mediante un fichero de
configuración, aún no tendríamos ninguna forma de envolver los objetos request yresponse.
Además, sin un mecanismo de buffer sofisticado, esta estrategia no proporcionará
post-procesamiento flexible.
La Estrategia de Filtro Estándar proporciona soluciones para estos
problemas, utilizando características de la especificación Servlet 2.3, que
proporciona una solución estándar al dilema de los filtros.
Standard Filter
Los filtros se controlan de forma declarativa utilizando un
descriptor de despliegue, según se describe en la especificación Servlet 2.3.
Esta especificación incluye un mecanismo estándar para construir cadenas de
filtos y poder añadir y eliminar filtros de esa cadena de forma transparente.
Los filtros se contruyen sobre interfaces, y se añaden o eliminan de una forma
declarativa modificando el descriptor de despliegue de una aplicación Web.
¿Por qué podría ser esto necesario? Los formularios HTML que incluyen
un uploadde
ficheros utilizan un tipo de codificación diferente a la mayoría de
formularios. Así, los datos del formulario que acompañan al upload no están
disponibles mediante simples llamadas agetParameter(). Por eso, creamos dos filtros
que preprocesen las peticiones, traduciendo todos los tipos de codificación en
un sólo formato consistente. El formato que elegimos es hacer que todos los
datos del formulario estén disponibles como atributos de la petición.
Un fitlro maneja la forma de codificación estándar para el
tipo application/x-www-form-urlencoded y
el otro maneja el tipo de codificación menos común multipart/form-data, que
se utiliza en los formularios que incluyen uploads. Los filtros traducen todos
los datos del formulario en atributos de la petición, para que el mecanismo
principal de manejo de peticiones pueda trabajar con todas las peticiones de la
misma manera. en lugar de hacerlo con los casos especiales de las diferentes
codificaciones.
El siguiente ejemplo muestra un filtro que traduce las peticiones
utilizando el esquema de codificación de formularios estándar:
public class StandardEncodeFilter
extends BaseEncodeFilter {
// Creates new StandardEncodeFilter
public StandardEncodeFilter() { }
public void doFilter(javax.servlet.ServletRequest
servletRequest,javax.servlet.ServletResponse
servletResponse,javax.servlet.FilterChain
filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
String contentType =
servletRequest.getContentType();
if ((contentType == null) ||
contentType.equalsIgnoreCase(
"application/x-www-form-urlencoded")) {
translateParamsToAttributes(servletRequest,
servletResponse);
}
filterChain.doFilter(servletRequest,
servletResponse);
}
private void translateParamsToAttributes(
ServletRequest request, ServletResponse response)
{
Enumeration paramNames =
request.getParameterNames();
while (paramNames.hasMoreElements()) {
String paramName = (String)
paramNames.nextElement();
String [] values;
values = request.getParameterValues(paramName);
System.err.println("paramName = " + paramName);
if (values.length == 1)
request.setAttribute(paramName, values[0]);
else
request.setAttribute(paramName, values);
}
}
}
El ejemplo siguiente muestra el filtro que maneja las traduciones
de las peticiones que utilizan el esquema de codificación multipart.:
public class MultipartEncodeFilter extends
BaseEncodeFilter {
public MultipartEncodeFilter() { }
public void doFilter(javax.servlet.ServletRequest
servletRequest, javax.servlet.ServletResponse
servletResponse,javax.servlet.FilterChain
filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
String contentType =
servletRequest.getContentType();
// Only filter this request if it is multipart
// encoding
if (contentType.startsWith(
"multipart/form-data")){
try {
String uploadFolder =
getFilterConfig().getInitParameter(
"UploadFolder");
if (uploadFolder == null) uploadFolder = ".";
/** The MultipartRequest class is:
* Copyright (C) 2001 by Jason Hunter
* <jhunter@servlets.com>. All rights reserved.
**/
MultipartRequest multi = new
MultipartRequest(servletRequest,
uploadFolder,
1 * 1024 * 1024 );
Enumeration params =
multi.getParameterNames();
while (params.hasMoreElements()) {
String name = (String)params.nextElement();
String value = multi.getParameter(name);
servletRequest.setAttribute(name, value);
}
Enumeration files = multi.getFileNames();
while (files.hasMoreElements()) {
String name = (String)files.nextElement();
String filename = multi.getFilesystemName(name);
String type = multi.getContentType(name);
File f = multi.getFile(name);
// At this point, do something with the
// file, as necessary
}
}
catch (IOException e)
{
LogManager.logMessage(
"error reading or saving file"+ e);
}
} // end if
filterChain.doFilter(servletRequest,
servletResponse);
} // end method doFilter()
}
El código de estos filtros se basa en la especificación servlet 2.3. También se usa un filtro base, desde el que descienden estos dos filtros. El filtro base mostrado en el siguiente ejemplo proporciona el comportamiento por defecto para los métodos de retrollamada del filtro estándar:
public class BaseEncodeFilter implements
javax.servlet.Filter {
private javax.servlet.FilterConfig myFilterConfig;
public BaseEncodeFilter() { }
public void doFilter(
javax.servlet.ServletRequest servletRequest,
javax.servlet.ServletResponse servletResponse,
javax.servlet.FilterChain filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
filterChain.doFilter(servletRequest,
servletResponse);
}
public javax.servlet.FilterConfig getFilterConfig()
{
return myFilterConfig;
}
public void setFilterConfig(
javax.servlet.FilterConfig filterConfig) {
myFilterConfig = filterConfig;
}
}
Abajo tenemos un extracto del descriptor de despliegue de la
aplicación Web que contiene este ejemplo. Muestra cómo se registran estos dos
filtros y luego los mapea a un recurso, en este caso un sencillo servlet de
prueba.
.
.
.
<filter>
<filter-name>StandardEncodeFilter</filter-name>
<display-name>StandardEncodeFilter</display-name>
<description></description>
<filter-class> corepatterns.filters.encodefilter.
StandardEncodeFilter</filter-class>
</filter>
<filter>
<filter-name>MultipartEncodeFilter</filter-name>
<display-name>MultipartEncodeFilter</display-name>
<description></description>
<filter-class>corepatterns.filters.encodefilter.
MultipartEncodeFilter</filter-class>
<init-param>
<param-name>UploadFolder</param-name>
<param-value>/home/files</param-value>
</init-param>
</filter>
.
.
.
<filter-mapping>
<filter-name>StandardEncodeFilter</filter-name>
<url-pattern>/EncodeTestServlet</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>MultipartEncodeFilter</filter-name>
<url-pattern>/EncodeTestServlet</url-pattern>
</filter-mapping>
.
En la siguiente figura podemos ver el diagrama de secuencia de
este ejemplo:

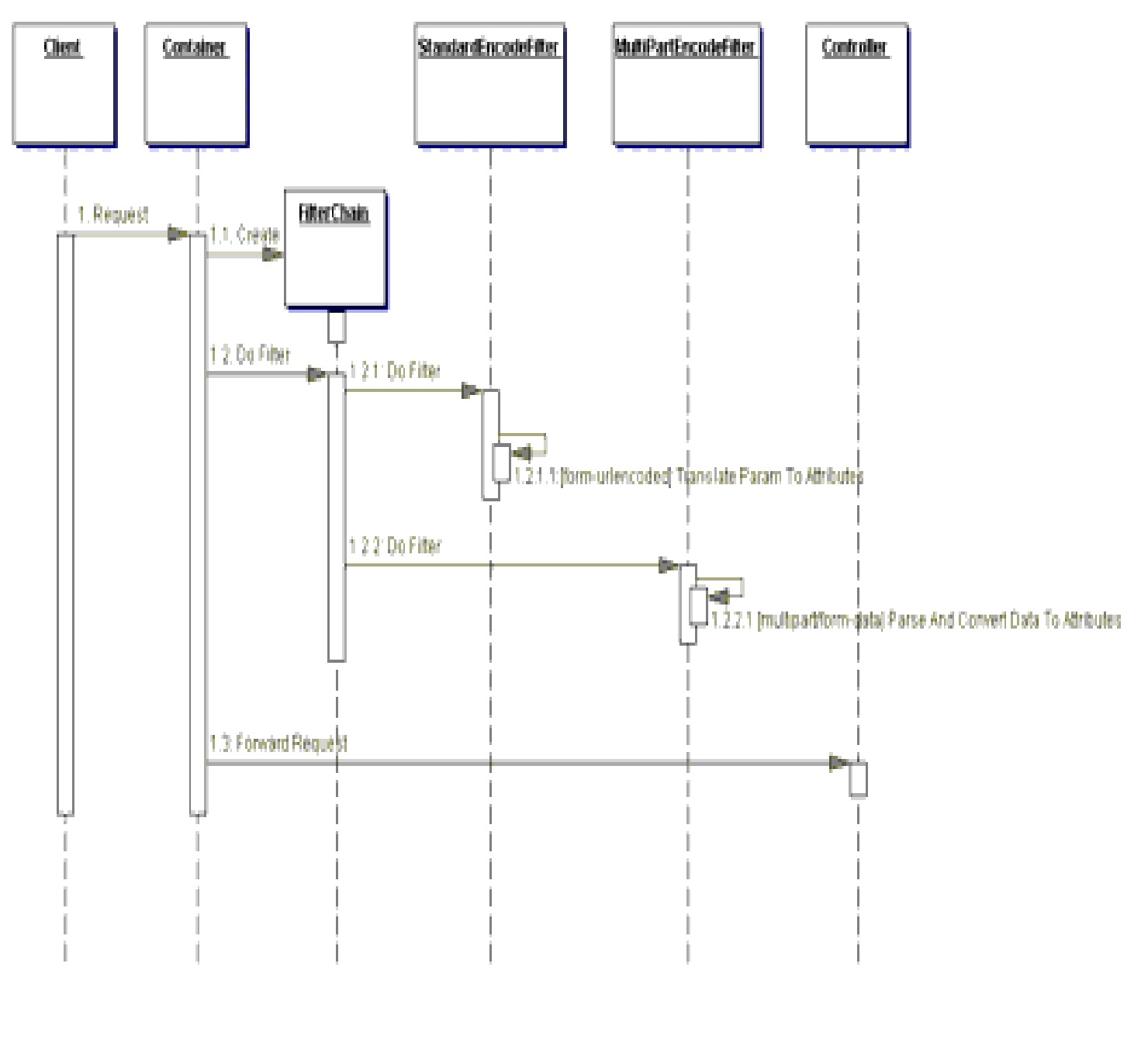{kind=link}
Los filtros StandardEncodeFilter y MultiPartEncodeFilter interceptan
el control cuando un cliente hace una petición al servlet controlador. El
contenedor acepta el rol de manejador de filtros y conduce el control a estos
filtros llamando a sus métodos doFilter. Después de completar su procesamiento,
cada filtro pasa el control al FilterChain que lo contiene, que está instruido
para ejecutar el siguiente filtro. Una vez que el control ha pasado por los dos
filtros, el siguiente componente en recibir el control es el recurso objetivo
real, en este caso el servlet controlador.
Los filtros, según lo soporta la especificación Servlet 2.3,
también soportan la envoltura de los objetos request y response. Esta
característica proporciona un mecanismo mucho más podereos que el que se puede
construir utilizando la implementación personlizada de la sección anterior. Por
supuesto, también podríamos construir una aproximación híbrida combinando las
dos estrategias.
Base Filter
Un filtro base sirve como una superclase común para todos los
filtros. Las características comunes se pueden encapsular en el filtro base y
se pueden compartir entre todos los filtros. Por ejemplo, un filtro base es un
buen lugar para incluir el comportamiento por defecto de los métodos de
retrollamada del contenedor, como hemos visto en la sección anterior. El
siguiente fragmento de código nos muestra cómo hacer esto:
public class BaseEncodeFilter implements javax.servlet.Filter { private javax.servlet.FilterConfig myFilterConfig; public BaseEncodeFilter() { } public void doFilter(javax.servlet.ServletRequest servletRequest,javax.servlet.ServletResponse servletResponse, javax.servlet.FilterChain filterChain) throws java.io.IOException, javax.servlet.ServletException { filterChain.doFilter(servletRequest, servletResponse); } public javax.servlet.FilterConfig getFilterConfig() { return myFilterConfig; } public void setFilterConfig(javax.servlet.FilterConfig filterConfig) { myFilterConfig = filterConfig; } }
Template Filter
Usar un filtro base del que descienden todos los demás permite a
la clase base proporcionar la funcionalidad de Plantilla de Métodos [GoF]. En
este caso, el filtro base se utiliza para dictar los pasos generales que debe
completar cada filtro, aunque deja las especifidades de cómo completar esos
pasos en la subclase de cada filtro. Normalmente, esto se definiría de forma
burda, métodos básicos que simplemente imponen una estructura limitada a cada
plantilla. Esta estrategia también se puede combinar con cualquier otra
estrategia de filtros. Los siguientes listados muestran como utilizar esta
estrategia con la Estrategia de Filtro Declarado:
public abstract class TemplateFilter implements javax.servlet.Filter { private FilterConfig filterConfig; public void setFilterConfig(FilterConfig fc) { filterConfig=fc; } public FilterConfig getFilterConfig() { return filterConfig; } public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { // Common processing for all filters can go here doPreProcessing(request, response, chain); // Common processing for all filters can go here doMainProcessing(request, response, chain); // Common processing for all filters can go here doPostProcessing(request, response, chain); // Common processing for all filters can go here // Pass control to the next filter in the chain or // to the target resource chain.doFilter(request, response); } public void doPreProcessing(ServletRequest request, ServletResponse response, FilterChain chain) { } public void doPostProcessing(ServletRequest request, ServletResponse response, FilterChain chain) { } public abstract void doMainProcessing(ServletRequest request, ServletResponse response, FilterChain chain); }
Dando esta definición de clase para TemplateFilter,
cada filtro se implementa como una subclase que sólo debe implementar el método doMainProcessing. Estas
subclases tienen la opción de implementar los otros tres métodos si lo desean.
Abajo tenemos un ejemplo de una subclase que implementa el método obligatorio
(dictado por nuestra plantilla de filtro) y el método de preprocesamiento
opcional.
public class DebuggingFilter extends TemplateFilter { public void doPreProcessing(ServletRequest req, ServletResponse res, FilterChain chain) { //do some preprocessing here } public void doMainProcessing(ServletRequest req, ServletResponse res, FilterChain chain) { //do the main processing; } }
En la siguiente figura podemos ver el diagrama de secuencia de
esta estrategia:

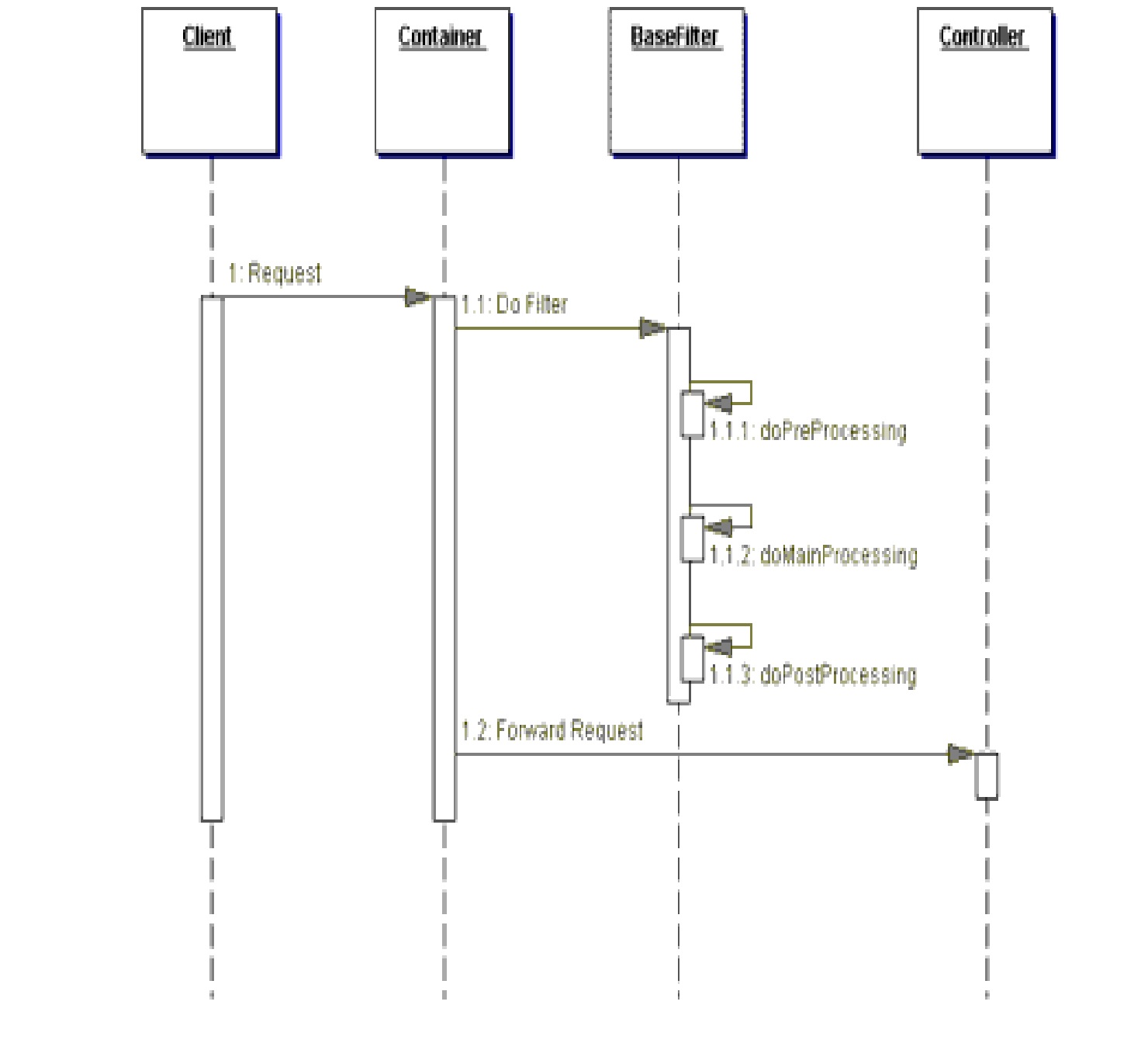{kind=link}
En el diagrama de secuencia, las subclases, como DebuggingFilter,
definen el procesamiento sobreescribiendo el método abstracto doMainProcessing, y,
opcionalmente,doPreProcessing y doPostProcessing. Así,
la plantilla de filtro impone una estructura para el procesamiento de todos los
filtros, así como proporciona un lugar para encapsular el código que es común
para cada filtro.
Consecuencias
- Centraliza
el Control con Controladores de Acoplamiento Ligero
Los filtros proporcionan un lugar centralaizado para controlar el procesamiento a través de múltiples peticiones, como lo hace el controlador. Los filtros están mejor preparados para manejar las peticiones y respuestas para el control último por un recurso objetivo, como un controlador. Además, un controlador frecuentemente junta el control de numerosos sevicios comunes y no relacionados, como la autentificación, el login, la encriptación, etc., mientras que los filtros nos permiten controladores de acoplamiento más ligero, que se pueden combinar. - Mejora la
Reutilización
Los filtros promueven la limpieza del particionamiento de la aplicación y aconsejan su reutilización. Estos interceptores conectables se añaden y eliminan al código existente de forma transparente y debido a su interface estándar, funcionan en cualquier combinación y son reutilizables por varias presentaciones. - Configuración
Declarativa y Flexible
Se pueden combinar numerosos servicios en varias permutaciones sin tener que recompilar ni una sola vez el código fuente. - La
Compartición Información es Ineficiente
Compartir información entre filtros puede ser ineficiente, porque por definición todo filtro tiene acoplamiento ligero. Si se deben compartir grandes cantidades de información entre los filtros, esta aproximación podría ser muy costosa. - Front
Controller
El controlador resuelve algunos problemas similares, pero está mejor diseñado para manejar el procesamiento principal. - Decorator [GoF]
El patrón Intercepting Filter está relacionado con el patrón Decorator, que proporciona envolturas conectables dinámicamente. - Template
Method [GoF]
El patrón de Plantillas de Métodos se utiliza para implementar la Estrategia de Plantilla de Filtros. - Interceptor
[POSA2]
El patrón Intercepting Filter está relacionado con el patron Interceptor, que permite que se pueden añadir servicios de forma transparente y dispararlos automáticamente.
No hay comentarios:
Publicar un comentario